Overview
SCEG-HiC predicts enhancer–gene links by integrating multi-omics single-cell data (either paired scATAC-seq/RNA-seq or scATAC-seq alone) with three-dimensional chromatin conformation information derived from bulk average Hi-C data. It employs the weighted graphical lasso (wglasso) model to incorporate average bulk Hi-C data, effectively regularizing the correlation matrix with the prior Hi-C contact matrix as a penalty term.
Installation
Required software
SCEG-HiC runs in the R statistical computing environment. It requires R version 4.1.0 or higher, Bioconductor version 3.14 or higher, and Seurat 4.0 or higher to access the latest features.
To install Bioconductor, open an R session and run:
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install(version = "3.14")Next, install a few Bioconductor packages that are not installed automatically:
BiocManager::install(c(
'BiocGenerics', 'DelayedArray', 'DelayedMatrixStats',
'limma', 'lme4', 'S4Vectors', 'SingleCellExperiment',
'SummarizedExperiment', 'batchelor', 'HDF5Array',
'terra', 'ggrastr', 'Gviz', 'rtracklayer', 'GenomeInfoDb', 'GenomicRanges'
))Installation of other dependencies
- Install the Signac pacakge:
devtools::install_github("timoast/signac", ref = "develop"). If you encounter any issues, please check the Signac documentation. - Install the Cicero package:
devtools::install_github("cole-trapnell-lab/cicero-release", ref = "monocle3"). If you encounter any issues, please check the Cicero installation guide.
Now, you can install the development version of SCEG-HiC from GitHub with:
# If you haven't installed devtools yet, uncomment and run:
# install.packages("devtools")
# Install the development version of SCEG-HiC from GitHub
devtools::install_github("wuwei77lx/SCEGHiC")If you prefer the stable release version from CRAN, run:
# Install the released version from CRAN
install.packages("SCEGHiC")Quickstart
This basic example demonstrates how to analyze paired scATAC-seq/RNA-seq data using SCEG-HiC:
library(SCEGHiC)
library(Signac)
# Load example multi-omics dataset
data(multiomic_small)
# Preprocess the data (aggregation)
SCEGdata <- process_data(multiomic_small, k_neigh = 5, max_overlap = 0.5)
#> Generating aggregated data
#> Aggregating cluster 0
#> Sample cells randomly.
#> There are 11 samples
#> Aggregating cluster 1
#> Sample cells randomly.
#> There are 11 samples
# Define genes of interest
gene <- c("TRABD2A", "GNLY", "MFSD6", "CTLA4", "LCLAT1", "NCK2", "GALM", "TMSB10", "ID2", "CXCR4")
# Get path to example average Hi-C data
fpath <- system.file("extdata", package = "SCEGHiC")
# Calculate Hi-C based weights for enhancer-gene pairs
weight <- calculateHiCWeights(SCEGdata, species = "Homo sapiens", genome = "hg38", focus_gene = gene, averHicPath = fpath)
#> Processing chromosome chr2...
#> Found 10 TSS loci on chr2.
#> Calculating Hi-C weights for gene TRABD2A...
#> Calculating Hi-C weights for gene GNLY...
#> Calculating Hi-C weights for gene MFSD6...
#> Calculating Hi-C weights for gene CXCR4...
#> Calculating Hi-C weights for gene CTLA4...
#> Calculating Hi-C weights for gene LCLAT1...
#> Calculating Hi-C weights for gene NCK2...
#> Calculating Hi-C weights for gene ID2...
#> Calculating Hi-C weights for gene GALM...
#> Calculating Hi-C weights for gene TMSB10...
#> Finished calculating Hi-C weights for all genes.
# Run the SCEG-HiC model
results_SCEGHiC <- Run_SCEG_HiC(SCEGdata, weight, focus_gene = gene)
#> Total predicted genes: 10
#> Running model for gene: TRABD2A
#> [1] "The optimal penalty parameter (rho) selected by BIC is: 0.43"
#> Running model for gene: GNLY
#> [1] "The optimal penalty parameter (rho) selected by BIC is: 0.19"
#> Running model for gene: MFSD6
#> [1] "The optimal penalty parameter (rho) selected by BIC is: 0.22"
#> Running model for gene: CXCR4
#> [1] "The optimal penalty parameter (rho) selected by BIC is: 0.14"
#> Running model for gene: CTLA4
#> [1] "The optimal penalty parameter (rho) selected by BIC is: 0.17"
#> Running model for gene: LCLAT1
#> [1] "The optimal penalty parameter (rho) selected by BIC is: 0.41"
#> Running model for gene: NCK2
#> [1] "The optimal penalty parameter (rho) selected by BIC is: 0.25"
#> Running model for gene: ID2
#> [1] "The optimal penalty parameter (rho) selected by BIC is: 0.13"
#> Running model for gene: GALM
#> [1] "The optimal penalty parameter (rho) selected by BIC is: 0.11"
#> Running model for gene: TMSB10
#> [1] "The optimal penalty parameter (rho) selected by BIC is: 0.44"
# Arc plot visualization predicted enhancer-gene links for CTLA4
connections_Plot(results_SCEGHiC, species = "Homo sapiens", genome = "hg38", focus_gene = "CTLA4", cutoff = 0.01, gene_anno = NULL)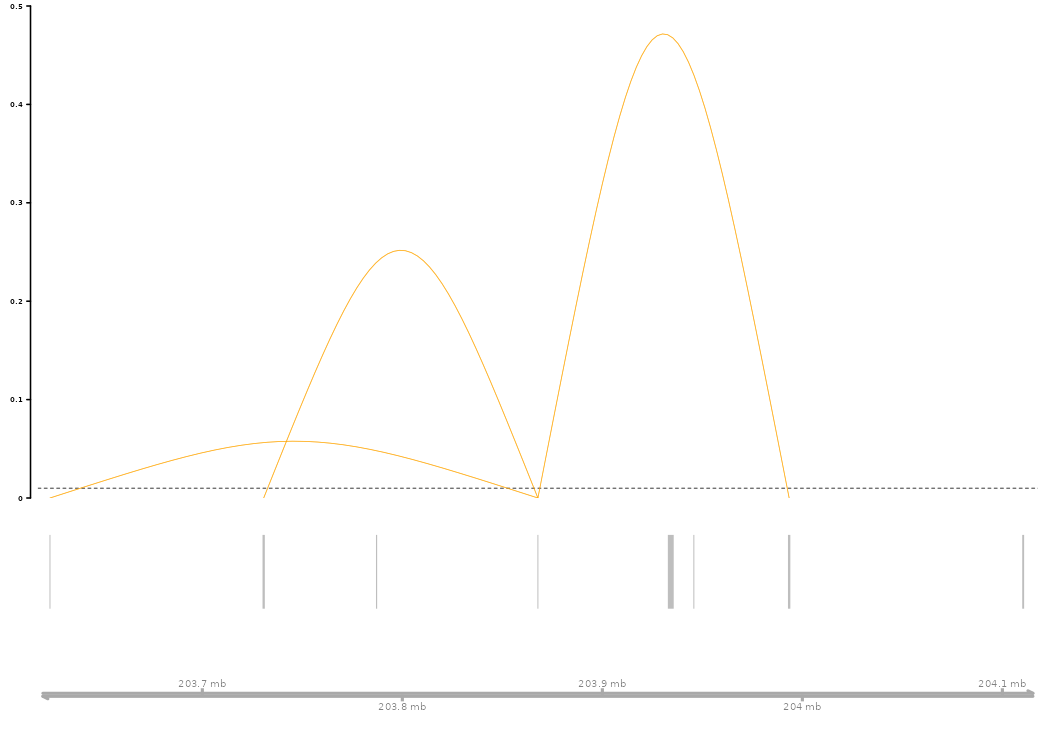
# Load fragment data for coverage plotting
frag_path <- system.file("extdata", "multiomic_small_atac_fragments.tsv.gz", package = "SCEGHiC")
frags <- CreateFragmentObject(path = frag_path, cells = colnames(multiomic_small))
#> Computing hash
Fragments(multiomic_small) <- frags
# Coverage plot and visualize the links of CTLA4
coverPlot(multiomic_small, focus_gene = "CTLA4", species = "Homo sapiens", genome = "hg38",
assay = "peaks", SCEG_HiC_Result = results_SCEGHiC, SCEG_HiC_cutoff = 0.01)
#> Warning in .merge_two_Seqinfo_objects(x, y): The 2 combined objects have no sequence levels in common. (Use
#> suppressWarnings() to suppress this warning.)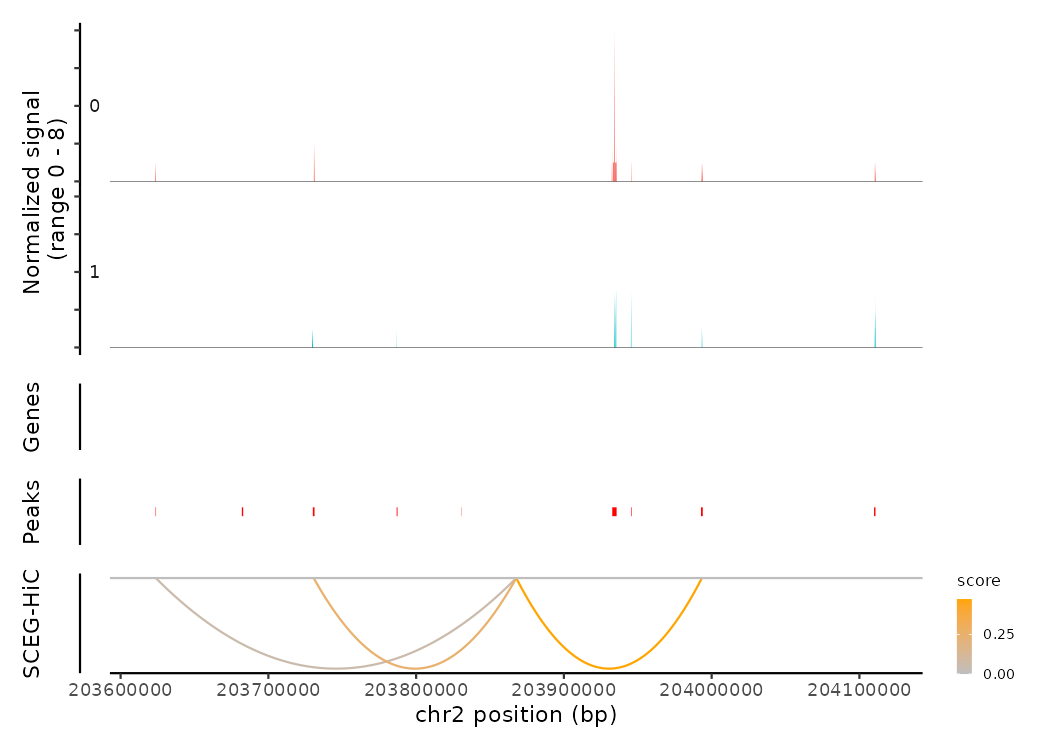
Session Info
sessionInfo()
#> R version 4.4.2 (2024-10-31)
#> Platform: x86_64-conda-linux-gnu
#> Running under: Rocky Linux 9.6 (Blue Onyx)
#>
#> Matrix products: default
#> BLAS/LAPACK: /home/liangxuan/conda/envs/test/lib/libopenblasp-r0.3.28.so; LAPACK version 3.12.0
#>
#> locale:
#> [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
#> [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
#> [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
#> [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
#> [9] LC_ADDRESS=C LC_TELEPHONE=C
#> [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: Asia/Shanghai
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats4 stats graphics grDevices utils datasets methods
#> [8] base
#>
#> other attached packages:
#> [1] harmony_1.2.3 Rcpp_1.0.14
#> [3] dplyr_1.1.4 ggplot2_3.5.1
#> [5] BSgenome.Hsapiens.UCSC.hg38_1.4.5 BSgenome_1.74.0
#> [7] rtracklayer_1.66.0 BiocIO_1.16.0
#> [9] Biostrings_2.74.1 XVector_0.46.0
#> [11] EnsDb.Hsapiens.v86_2.99.0 ensembldb_2.30.0
#> [13] AnnotationFilter_1.30.0 GenomicFeatures_1.58.0
#> [15] AnnotationDbi_1.68.0 Biobase_2.66.0
#> [17] GenomicRanges_1.58.0 GenomeInfoDb_1.42.1
#> [19] IRanges_2.40.1 S4Vectors_0.44.0
#> [21] BiocGenerics_0.52.0 Seurat_5.2.0
#> [23] SeuratObject_5.0.2 sp_2.1-4
#> [25] Signac_1.14.9001 SCEGHiC_1.0.1
#>
#> loaded via a namespace (and not attached):
#> [1] fs_1.6.5 ProtGenerics_1.38.0
#> [3] matrixStats_1.5.0 spatstat.sparse_3.1-0
#> [5] bitops_1.0-9 httr_1.4.7
#> [7] RColorBrewer_1.1-3 tools_4.4.2
#> [9] sctransform_0.4.1 backports_1.5.0
#> [11] R6_2.5.1 lazyeval_0.2.2
#> [13] uwot_0.2.2 Gviz_1.50.0
#> [15] cicero_1.3.9 withr_3.0.2
#> [17] prettyunits_1.2.0 gridExtra_2.3
#> [19] progressr_0.15.1 textshaping_1.0.1
#> [21] cli_3.6.3 spatstat.explore_3.3-4
#> [23] fastDummies_1.7.4 labeling_0.4.3
#> [25] slam_0.1-55 sass_0.4.9
#> [27] spatstat.data_3.1-4 ggridges_0.5.6
#> [29] pbapply_1.7-2 systemfonts_1.1.0
#> [31] Rsamtools_2.22.0 foreign_0.8-88
#> [33] R.utils_2.12.3 dichromat_2.0-0.1
#> [35] parallelly_1.41.0 VGAM_1.1-12
#> [37] rstudioapi_0.17.1 RSQLite_2.3.9
#> [39] FNN_1.1.4.1 generics_0.1.3
#> [41] ica_1.0-3 spatstat.random_3.3-2
#> [43] Matrix_1.6-5 interp_1.1-6
#> [45] ggbeeswarm_0.7.2 abind_1.4-8
#> [47] R.methodsS3_1.8.2 lifecycle_1.0.4
#> [49] yaml_2.3.10 SummarizedExperiment_1.36.0
#> [51] SparseArray_1.6.0 BiocFileCache_2.14.0
#> [53] Rtsne_0.17 grid_4.4.2
#> [55] blob_1.2.4 promises_1.3.2
#> [57] crayon_1.5.3 miniUI_0.1.1.1
#> [59] lattice_0.22-6 cowplot_1.1.3
#> [61] KEGGREST_1.46.0 pillar_1.10.1
#> [63] knitr_1.49 boot_1.3-31
#> [65] rjson_0.2.23 future.apply_1.11.3
#> [67] codetools_0.2-20 fastmatch_1.1-6
#> [69] glue_1.8.0 spatstat.univar_3.1-1
#> [71] data.table_1.16.4 Rdpack_2.6.2
#> [73] vctrs_0.6.5 png_0.1-8
#> [75] spam_2.11-0 gtable_0.3.6
#> [77] assertthat_0.2.1 cachem_1.1.0
#> [79] xfun_0.50 rbibutils_2.3
#> [81] S4Arrays_1.6.0 mime_0.12
#> [83] reformulas_0.4.0 survival_3.8-3
#> [85] SingleCellExperiment_1.28.1 RcppRoll_0.3.1
#> [87] fitdistrplus_1.2-2 ROCR_1.0-11
#> [89] nlme_3.1-166 usethis_3.1.0
#> [91] bit64_4.5.2 progress_1.2.3
#> [93] filelock_1.0.3 RcppAnnoy_0.0.22
#> [95] rprojroot_2.0.4 bslib_0.8.0
#> [97] irlba_2.3.5.1 vipor_0.4.7
#> [99] KernSmooth_2.23-26 rpart_4.1.24
#> [101] colorspace_2.1-1 DBI_1.2.3
#> [103] Hmisc_5.2-2 nnet_7.3-20
#> [105] ggrastr_1.0.2 tidyselect_1.2.1
#> [107] bit_4.5.0.1 compiler_4.4.2
#> [109] curl_6.0.1 httr2_1.0.7
#> [111] htmlTable_2.4.3 xml2_1.5.0
#> [113] desc_1.4.3 DelayedArray_0.32.0
#> [115] plotly_4.10.4 checkmate_2.3.2
#> [117] scales_1.4.0 lmtest_0.9-40
#> [119] rappdirs_0.3.3 stringr_1.5.1
#> [121] digest_0.6.37 goftest_1.2-3
#> [123] minqa_1.2.8 spatstat.utils_3.1-2
#> [125] reader_1.0.6 rmarkdown_2.29
#> [127] RhpcBLASctl_0.23-42 htmltools_0.5.8.1
#> [129] pkgconfig_2.0.3 jpeg_0.1-10
#> [131] base64enc_0.1-3 lme4_1.1-36
#> [133] MatrixGenerics_1.18.1 dbplyr_2.5.0
#> [135] fastmap_1.2.0 rlang_1.1.4
#> [137] htmlwidgets_1.6.4 UCSC.utils_1.2.0
#> [139] shiny_1.10.0 farver_2.1.2
#> [141] jquerylib_0.1.4 zoo_1.8-12
#> [143] jsonlite_1.8.9 BiocParallel_1.40.0
#> [145] R.oo_1.27.0 VariantAnnotation_1.52.0
#> [147] RCurl_1.98-1.16 magrittr_2.0.3
#> [149] Formula_1.2-5 GenomeInfoDbData_1.2.13
#> [151] dotCall64_1.2 patchwork_1.3.0
#> [153] reticulate_1.40.0 stringi_1.8.7
#> [155] zlibbioc_1.52.0 MASS_7.3-64
#> [157] plyr_1.8.9 parallel_4.4.2
#> [159] listenv_0.9.1 ggrepel_0.9.6
#> [161] deldir_2.0-4 splines_4.4.2
#> [163] tensor_1.5 hms_1.1.3
#> [165] igraph_2.0.3 spatstat.geom_3.3-4
#> [167] RcppHNSW_0.6.0 reshape2_1.4.4
#> [169] biomaRt_2.62.0 XML_3.99-0.17
#> [171] evaluate_1.0.3 latticeExtra_0.6-30
#> [173] biovizBase_1.54.0 NCmisc_1.2.0
#> [175] nloptr_2.1.1 tweenr_2.0.3
#> [177] httpuv_1.6.15 RANN_2.6.2
#> [179] tidyr_1.3.1 purrr_1.0.2
#> [181] polyclip_1.10-7 future_1.34.0
#> [183] scattermore_1.2 ggforce_0.4.2
#> [185] monocle3_1.3.7 xtable_1.8-4
#> [187] restfulr_0.0.15 RSpectra_0.16-2
#> [189] roxygen2_7.3.3 later_1.4.1
#> [191] ragg_1.3.3 glasso_1.11
#> [193] viridisLite_0.4.2 tibble_3.2.1
#> [195] beeswarm_0.4.0 memoise_2.0.1
#> [197] GenomicAlignments_1.42.0 cluster_2.1.8
#> [199] globals_0.16.3See the documentation website for more information!
The bulk average Hi-C data
The human cell types used for averaging are based on 34 Hi-C datasets from the ENCODE project.
The mouse cell types used for averaging are: two embryonic stem cell types (mESC1, mESC2), CH12LX, CH12F3, fiber, epithelium, and B cells.
The bulk average Hi-C data can be generated using the Activity by Contact (ABC) model’s makeAverageHiC.py script.
Download Links for Average Hi-C Data
-
Human bulk average Hi-C (~54.1 GB)
Download from: ENCFF134PUN.bed.gz.
After downloading, extract the human bulk average Hi-C using the Activity by Contact (ABC) model’s extract_avg_hic.py script:
-
Mouse bulk average Hi-C (~13.9 GB)
Download from: 10.5281/zenodo.14849886.
For more details about bulk average Hi-C data, please visit: https://github.com/wuwei77lx/compare_model.
Example
In SCEG-HiC, you can choose either aggregation or single-cell retention approach:
Aggregation approach: Aggregates binarized scATAC-seq data across cell types using k-nearest neighbor smoothing to reduce data sparsity. This approach captures a broader spectrum of enhancer-gene links across cell types, with slightly reduced prediction accuracy.
Single-cell retention approach: Normalizes scATAC-seq data within individual cell types to individual cell signals. This method achieves higher precision and accuracy, albeit identifying fewer enhancer-gene links
Recommendation: To balance accuracy and coverage, we implemented both preprocessing strategies in SCEG-HiC, with aggregation designated as the default. The single-cell retention approach can be optionally used when higher precision within specific cell types is desired.
For more details and real data examples, please visit:
SCEG-HiC on paired scATAC-seq/RNA-seq data of PBMC (aggregation)
SCEG-HiC on paired scATAC-seq/RNA-seq data of mouse skin (aggregation)
SCEG-HiC on scATAC-seq data alone from human COVID-19 monocytes
Alternatively, when applying SCEG-HiC to a new tissue, the penalty strength can be adjusted using the alpha parameter (alpha * rho):
Increase alpha is suitable for tissues well represented in the datasets used to construct the bulk average Hi-C map, to allow greater reliance on prior Hi-C contact information.
Decrease alpha is preferable for more unique tissues or conditions, to reduce dependence on prior Hi-C contact information and emphasize single-cell data.
# Example: run SCEG-HiC with scaled penalty
results_SCEGHiC <- Run_SCEG_HiC(SCEGdata, weight, focus_gene = gene, alpha=1.5)Notes:
alpha = 1uses the original penalty (default).alpha > 1strengthens the penalty.alpha < 1weakens the penalty.
Help
If you have any questions, comments, or suggestions, please contact Xuan Liang at liangxuan2022@sinh.ac.cn.